摘要:AI产品开发者需要先行一步,早一些让用户体验自己的产品,和用户建立连接,培养粘性,从而在竞争中占得先机。
2024注定是AI行业热闹非凡的一年。虽然刚刚进入3月份,但是关于AI的新闻已经多次占据了头条。就在上个月,OpenAI发布了文字生成视频的大模型Sora,其逼真的效果直接清空了在这个细分赛道苦苦耕耘的创业者。几天后,英伟达市值站上2万亿美元,成为了历史上最快实现从1万亿到2万亿美元市值的企业。正所谓“当你发现金矿,最好的生意不是挖矿而是卖铲子”,英伟达成为了AI时代“军备竞赛”的最大赢家。
就在大家感叹“世界上只有两种AI,一种叫OpenAI,一种叫其他AI”的时候,沉寂了许久的Anthropic放出王炸,这家由OpenAI前研究副总裁创立的公司,发布了最新的Claude3模型,各项指标已经全面超越了GPT4。
AI行业的风起云涌,也昭示了这个行业还处在一个初级阶段。技术迭代太快,暂时领先的企业可能在一夜之间就被新技术颠覆。一些眼花缭乱的新技术,虽然已经问世,但迟迟不公开或者没有部署。比如上文提到的Sora,截至发文,还没有正式向公众开放。
生成式AI的研发和本地部署之间存在鸿沟。目前,大众使用的生成式AI产品往往是部署在云端而在本地访问(比如ChatGPT网页),但这无法满足所有需求,并且会产生一些隐患。
首先,随着大模型越来越复杂,云端和本地之间的传输在有限带宽下变得捉襟见肘,比如一架波音787飞机每秒钟产生5G的数据,如果上传到云端、计算、输出结果再返回,飞机可能已经飞出去几公里了(按照800公里/小时估算)。如果在飞机上使用AI功能但是在云端部署,这样的传输速度是无法满足要求的。
此外,一些用户敏感数据、隐私数据,是否一定要上云?显然放在本地比云端更让用户放心。
不论生成式AI多么强大,如何部署到本地始终是一个无法绕开的问题。这是行业发展的趋势,虽然目前面临一些困难。
困难在于,如何把“大模型”装入“小设备”。注意,这里的“大小”是相对而言的。云端计算的背后可能是一个占地几万平方米的计算中心,而本地部署却要让生成式AI在你的手机上跑起来。手机没有液氮冷却,也没有无穷无尽的电力,该如何部署AI呢?
异构计算,一种可能的解决方案?
高通的异构计算AI引擎(以下皆称作高通AI引擎)为行业提供了一种可行的解决方案。即通过CPU、GPU、NPU以及高通传感器中枢和内存子系统的协作,实现了AI部署和大幅度提升AI体验的目的。

图:专门的工业设计让不同计算单元更紧凑 来源:高通
不同类型的处理器所擅长的工作不同,异构计算的原理就是让“专业的人做专业的事”。CPU擅长顺序控制,适用于需要低延时的应用场景,同时,一些较小的传统模型如卷积神经网络模型(CNN),或一些特定的大语言模型(LLM),CPU处理起来也能得心应手。而GPU更擅长面向高精度格式的并行处理,比如对画质要求非常高的视频、游戏。
CPU和GPU出镜率很高,大众已经相当熟悉,而NPU相对而言更像一种新技术。NPU即神经网络处理器,专门为实现低功耗、加速AI推理而打造。当我们在持续使用AI时,需要以低功耗稳定输出高峰值性能,NPU就可以发挥最大优势。
举个例子,当用户在玩一款重负载的游戏,此时GPU会被完全占用,或者用户在浏览多个网页,CPU又被完全占用。此时,NPU作为真正的AI专用引擎就会负担起和AI有关的计算,保证用户的AI体验流畅。
总结起来说就是,CPU和GPU是通用处理器,为灵活性而设计,易于编程,本职工作是负责操作系统、游戏和其他应用。NPU则为AI而生,AI是它的本职工作,通过牺牲部分易编程特性而实现了更高的峰值性能和能效,一路为用户的AI体验护航。
当我们把 CPU、GPU、NPU 以及高通传感器中枢和内存子系统集成在一起,就是异构计算架构。
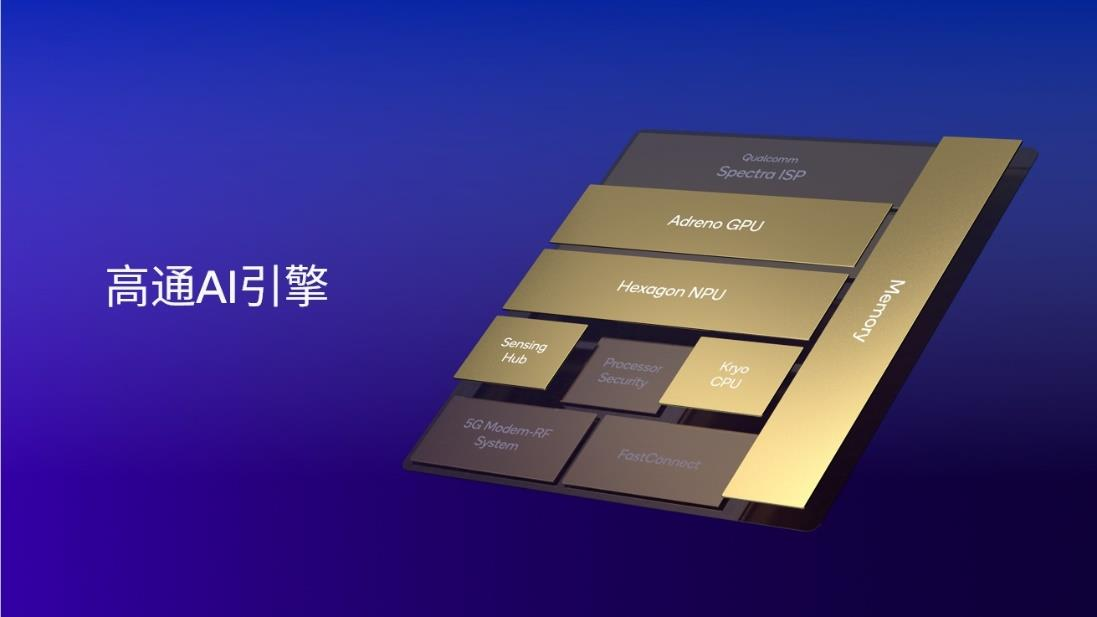
图:高通AI引擎包括Hexagon NPU、Adreno GPU、高通Oryon或 Kryo CPU、高通传感器中枢和内存子系统 来源:高通
高通AI引擎整合了高通 Oryon 或 Kryo CPU、 Adreno GPU 、 Hexagon NPU 以及高通传感器中枢和内存子系统。Hexagon NPU作为其中的核心组件,经过多年的升级迭代,目前已达到业界领先的AI处理水平。以手机平台为例,集成高通 AI 引擎的第三代骁龙 8 支持行业领先的LPDDR5x内存,频率高达4.8GHz,使其能够以非常高速的芯片内存读取速度运行大型语言模型,如百川、Llama 2等,从而实现非常快的token生成速率,为用户带来全新的体验。
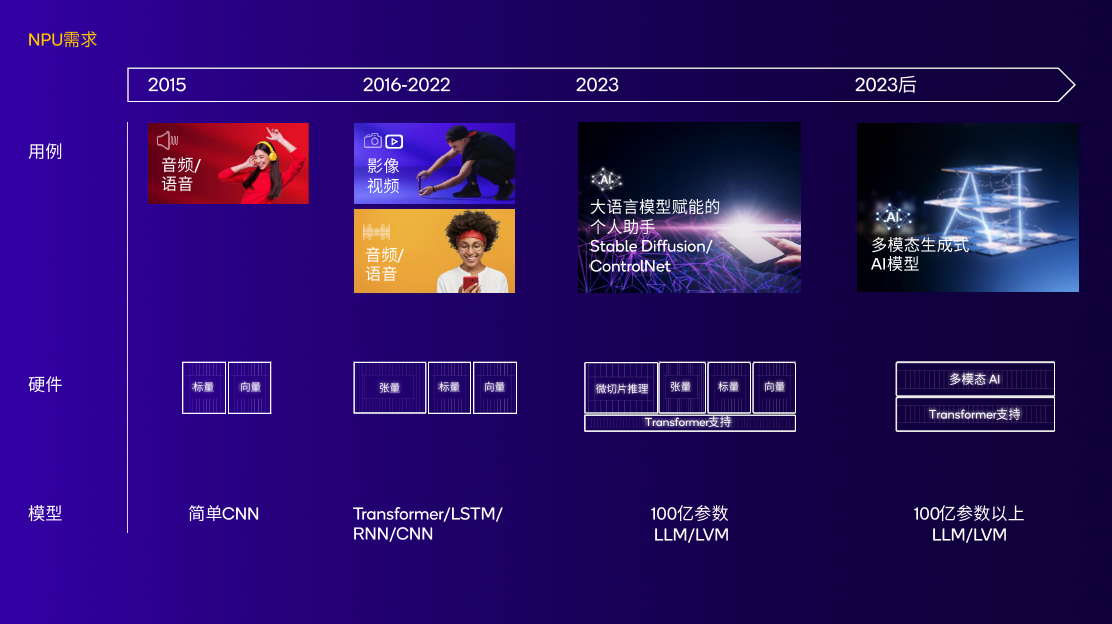
图:NPU随着不断变化的AI用例和模型持续演进,实现高性能低功耗 来源:高通
高通对NPU的研究,并不是近几年才开始的。如果要追溯Hexagon NPU的起源,要回到2007年,也就是生成式AI走入公众视野的15年前。高通发布的首款Hexagon DSP在骁龙平台上亮相,DSP控制和标量架构成为了高通未来多代NPU的基础。
8年后,也就是2015年,骁龙820处理器集成了首个高通AI引擎;
2018年,高通在骁龙855中为Hexagon NPU增加了张量加速器;
2019年,高通在骁龙865上扩展了终端侧AI用例,包括AI成像、AI视频、AI语音等功能;
2020年,Hexagon NPU迎来变革型架构更新。标量、向量、张量加速器融合,这为高通未来的NPU架构奠定了基础;
2022年,第二代骁龙8中的Hexagon NPU引入了一系列重大技术提升。微切片技术提升了内存效率,功耗降低继续降低并且实现了4.35倍的AI性能提升。
2023年10月25日,高通正式发布第三代骁龙8。作为高通技术公司首个专为生成式AI而精心打造的移动平台,其集成的Hexagon NPU是目前高通面向生成式AI最新、也是最好的设计。
由于高通为AI开发者和下游厂商提供的是全套解决方案(这部分内容会在第三部分详细叙述),并非单独提供芯片或者某个软件应用。这意味着在硬件设计上和优化上,高通可以通盘考虑,找出目前AI开发的瓶颈,做有针对性地提升。
比如,为何要特别在意内存带宽这个技术点?当我们把视角从芯片上升到AI大模型开发,就会发现内存带宽是大语言模型token生成的瓶颈。第三代骁龙8的NPU架构之所以能帮助加速开发AI大模型,原因之一便在于专门提升了内存带宽的效率。
这种效率的提升主要受益于两项技术的应用。
第一是微切片推理。通过将神经网络分割成多个独立执行的微切片,消除了高达10余层的内存占用,此举最大化利用了Hexagon NPU中的标量、向量和张量加速器并降低功耗。第二是本地4位整数(INT4)运算。它能将INT4层和神经网络和张量加速吞吐量提高一倍,同时提升了内存带宽效率。
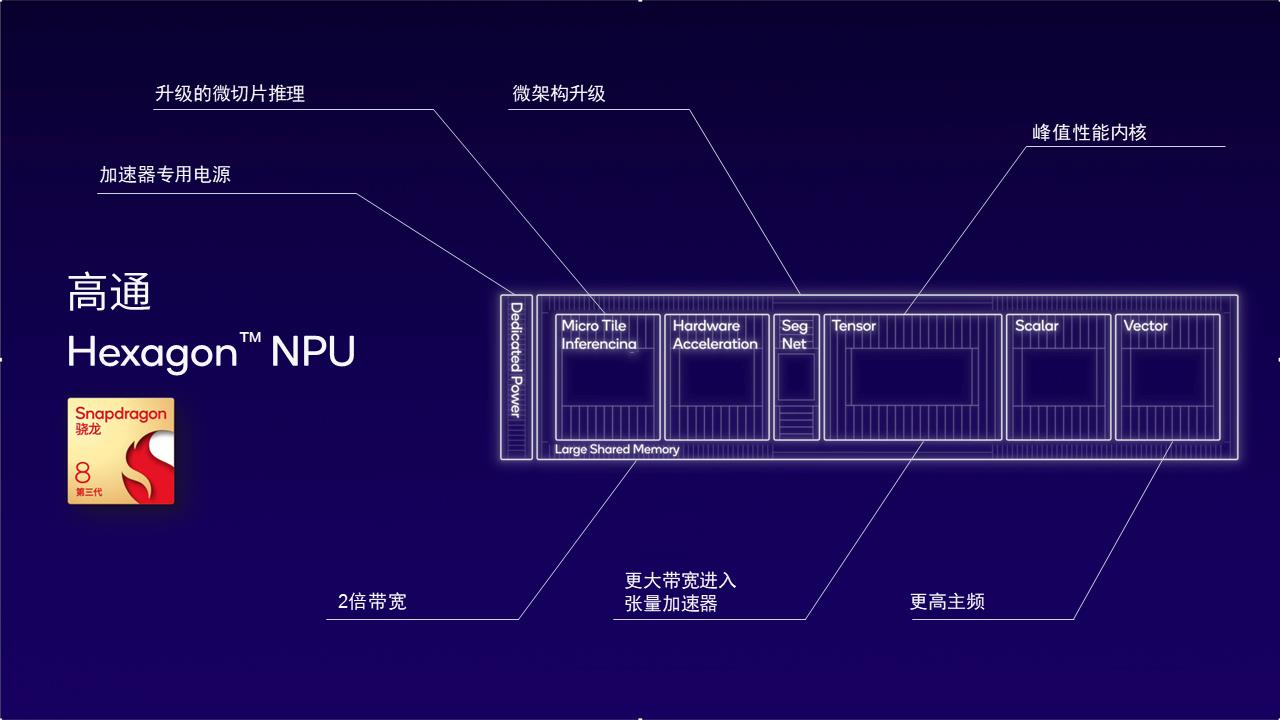
图:第三代骁龙8的Hexagon NPU以低功耗实现更佳的AI性能
2月26日,世界移动通信大会(MWC 2024)在巴塞罗那拉开帷幕。基于骁龙X Elite,高通向全世界展示了全球首个在终端侧运行的超过70亿参数的大型多模态语言模型(LMM)。该模型可接收文本和音频输入(如音乐、交通环境音频等),并基于音频内容生成多轮对话。
所以,在集成了Hexagon NPU的移动终端上,会有怎样的AI体验?以及它是如何做到的?高通详细拆解了一个案例。
借助移动终端的AI旅行助手,用户可以直接对模型提出规划旅游行程的需求。AI助手可以立刻给到航班行程建议,并且通过语音对话调整输出结果,最后通过Skyscanner插件创建完整航班日程。
这种一步到位的体验是如何实现的?
第一步,用户的语音通过自动语音识别(ASR)模型Whisper转化成文本。该模型有2.4亿个参数,主要在高通传感器中枢上运行;
第二步,利用Llama 2或百川大语言模型基于文本内容生成文本回复,这一模型在Hexagon NPU上运行;
第三步,通过在CPU上运行的开源TTS(Text to Speech)模型将文本转化为语音;
最后一步,通过调制解调器技术进行网络连接,使用Skyscanner插件完成订票操作。
行业井喷前夕,开发者需要抢占先机
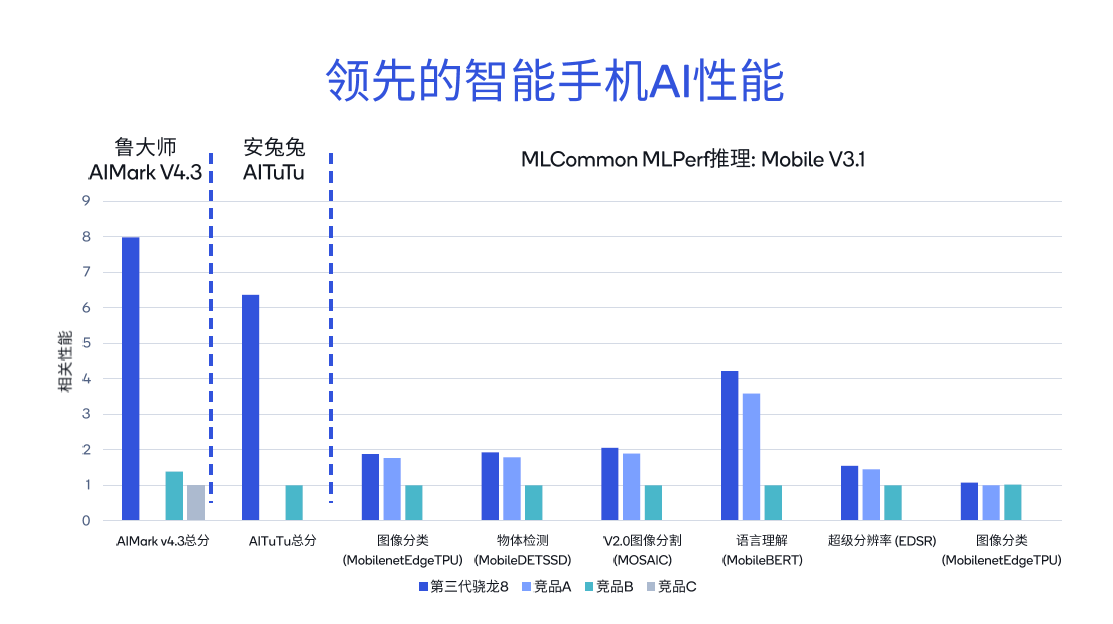
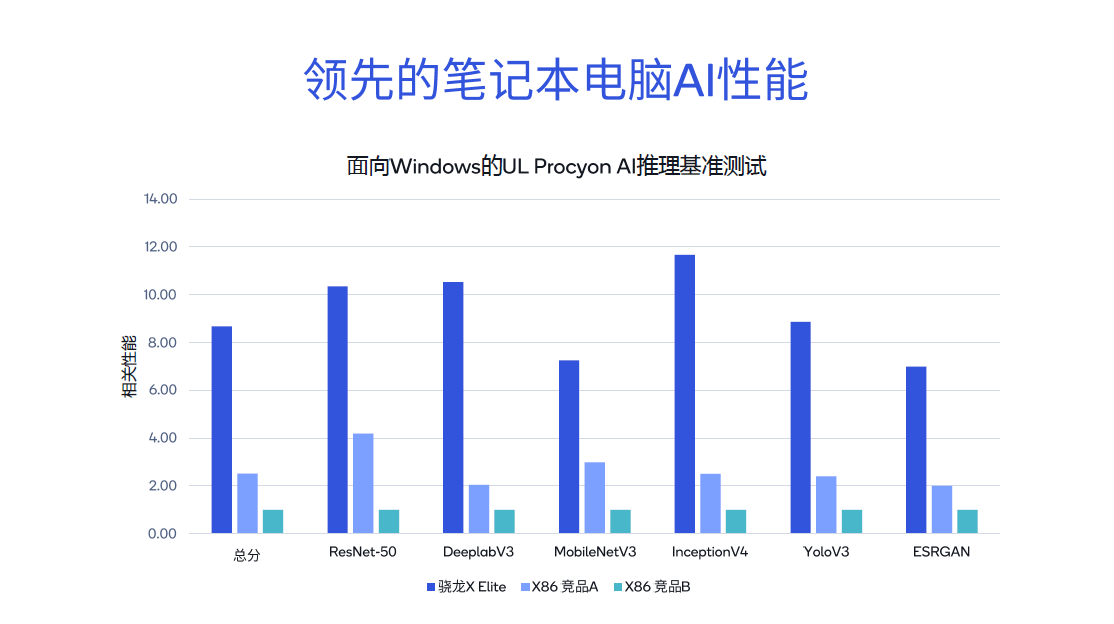
使用不同的工具测试骁龙和高通平台的AI性能表现,可以发现其得分比同类竞品高出几倍。从鲁大师AIMark V4.3基准测试结果来看,第三代骁龙8的总分相较竞品B高出5.7倍,而相较竞品C高出7.9倍。
在安兔兔AITuTu基准测试中,第三代骁龙8的总分比竞品B高出6.3倍。针对MLCommon MLPerf推理的不同子项,包括图像分类、语言理解以及超级分辨率等,也进行了详尽的比较。
进一步对比骁龙X Elite与其他X86架构竞品,在ResNet-50、DeeplabV3等测试中,骁龙X Elite表现出明显的领先地位,其基准测试总分分别是X86架构竞品A的3.4倍和竞品B的8.6倍。因此,在PC端,无论是运行Microsoft Copilot,还是进行文档摘要、文档撰写等生成式AI应用,体验都十分流畅。
领先的AI性能不全是高通AI引擎的功劳,确切的说,高通对AI厂商的赋能是全方位的。
首先是高通AI引擎。它包括Hexagon NPU、Adreno GPU、高通Oryon CPU(PC平台)、高通传感器中枢和内存子系统。专门的工业设计、不同部件之间良好的协同,这款异构计算架构为终端侧产品提供了低功耗、高能效的开发平台。
基于先进的硬件,高通又推出了AI软件栈(高通AI Stack)。这款产品的诞生是为了解决AI开发中的顽疾——同一个功能,针对不同平台要多次开发,重复劳动。AI Stack支持目前所有的主流AI框架,OEM厂商和开发者可以在平台上创建、优化和部署AI应用,并且能实现“一次开发,全平台部署”,大大减少了研发人员的重复劳动。

图:高通AI软件栈帮助开发者“一次开发,全平台部署” 来源:高通
此外,还有高通在MWC2024上刚刚发布的AI Hub。AI Hub是一个包含了近80个AI模型的模型库,其中既有生成式AI模型,也有传统AI模型,还包括图像识别或面部识别模型,百川、Stable Diffusion、Whisper等模型。开发者可以从AI Hub中选取想要使用的模型生成二进制插件,做到AI 开发的“即插即用”。

综合来说,如果纵向看深度,高通在硬件(AI引擎)、软件(AI Stack)和素材库(AI Hub)三个维度全面加速厂商的AI开发进度。横向看覆盖广度,高通的产品已经覆盖了几乎所有的终端侧设备(第三代骁龙8支持手机等终端,X Elite赋能AI PC产品)。
AI应用处于井喷前的酝酿期。
在教育领域,AI能针对学生的学习能力和进度制定个性化的教学方案;在医学领域, AI可以用来发掘全新的抗生素类型;在养老方面,未来在一些社会老龄化问题比较严重的地区,可以利用AI终端收集老年人家中的所有个人数据,从而帮助预防紧急医疗事故。
之所以叫“井喷前”,正是因为还没有大规模部署。另一方面,AI应用,作为最容易让用户产生粘性的产品之一,具有很强的先发优势效应。
AI产品开发者需要先行一步,早一些让用户体验自己的产品,和用户建立连接,培养粘性,从而在竞争中占得先机。
(文章转载自DeepTech深科技)
郑重声明:此文内容为本网站转载企业宣传资讯,目的在于传播更多信息,与本站立场无关。仅供读者参考,并请自行核实相关内容。
-
 回购+自购,真金白银进场护盘近期A/H两地股市表现不佳,对于股市何时触底,没有人知道,但近期无论是上市公司本...
回购+自购,真金白银进场护盘近期A/H两地股市表现不佳,对于股市何时触底,没有人知道,但近期无论是上市公司本... -
 “90后”海归村干部抗疫日记:多幸运我有“90后”海归村干部抗疫日记:多幸运我有个“我们”题:“90后”海归村干部抗疫日...
“90后”海归村干部抗疫日记:多幸运我有“90后”海归村干部抗疫日记:多幸运我有个“我们”题:“90后”海归村干部抗疫日... -
 “宁王”大跌40%!“聪明钱”爆买20亿本周,A股一度大幅调整,成交量屡创年内新低。北上资金先抑后扬,前半周随市场波动而...
“宁王”大跌40%!“聪明钱”爆买20亿本周,A股一度大幅调整,成交量屡创年内新低。北上资金先抑后扬,前半周随市场波动而...



















-
AI手机AI PC井喷在即 高通在加速布局以赋能生态
2024-03-12 11:33
-
专业级拍摄表现 荣耀100 Pro造就中端影像之王
2024-03-12 10:55
-
全友案例丨一体转角柜好酷!被这个88㎡案例惊艳了
2024-03-12 09:56
-
全友家居沙发丨“质”美双全,坐享新“适”界
2024-03-12 09:55
-
禾赛HSAI.US公布2023年第四季度及全年财报:
2024-03-12 09:23
-
安胜国际发起审计凸显其资本保护领域领导者的地位
2024-03-12 09:01
-
地方两会观察丨推动融合创新为“诗与远方”添彩——从地
2024-03-12 05:18
-
湖南先施制药有限公司申请II类会议
2024-03-12 05:07
-
华尔街最悲观基金经理:股市恐慌情绪已经形成暴跌或近在
2024-03-12 04:57
-
英伟达-5%发生了什么...
2024-03-12 04:18
-
发展新质生产力如何用好产业政策?赵波:厘清政府和市场
2024-03-12 04:03
-
国家统计局:2月份CPI同比上涨0.7%环比上涨1.
2024-03-12 03:37
-
李卫国堵不了的漏
2024-03-12 03:16
-
探索电商行业高质量发展路线,梦饷科技蝉联“2023年
2024-03-12 03:02
-
天气丨近期苏城气温将有小幅波动
2024-03-12 02:23


{kind=link}
{kind=link}